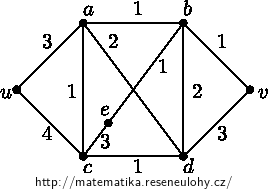
Vyplňujeme tabulku, kde pro jednotlivé vrcholy uvádíme odhad \(d\) vzdálenosti od \(u\), právě zpracovaný vrchol \(x\) a množinu zpracovaných vrcholů \(Z\). Řádek vyznačuje hodnoty \(d, x\) a \(Z\) po provedení příslušné iterace.
\(
\begin{array}{c|ccccccc|c|l}
\# & u & a & b & c & d & e & v & x & Z \\
0 & 0 & \infty & \infty & \infty & \infty & \infty & \infty & & \emptyset \\
1 & 0 & 3 & \infty & 4 & \infty & \infty & \infty & u & u \\
2 & 0 & 3 & 5 & 4 & 5 & \infty & \infty & a & u,a \\
3 & 0 & 3 & 5 & 4 & 5 & 7 & \infty & c & u,a,c \\
4 & 0 & 3 & 5 & 4 & 5 & 7 & 8 & d & u,a,c,d \\
5 & 0 & 3 & 5 & 4 & 5 & 7 & 6 & b & u,a,c,d,b \\
6 & 0 & 3 & 5 & 4 & 5 & 6 & 6 & v & u,a,c,d,b, v \\
\end{array}
\)
Všimněte si, že průběh algoritmu není jednoznačný. Ve čtvrté iteraci jsme volili \(x\) mezi \(d\) a \(b\). Podobně v poslední iteraci mohlo být zvoleno \(e\) namísto \(v\) . Algoritmus by pak měl o jednu iteraci více.
Ne všechny vrcholy byly zpracovány. Na konci algoritmu \(e \notin Z\).
")


